As a consultant, I often address how businesses can leverage advanced large language models like ChatGPT, tailoring AI with their proprietary data to generate unique insights and solutions.
Imagine trying to teach a machine to generate sarcasm but instead it's hurling insults. That was me, some time ago, designing a lesson for a class on a peculiar type of machine learning model—one that I had a class of students labeling sarcastic comments I'd collected from Reddit as either "scarastic" or "not_sarcastic". My aim? To spark engagement and showcase the quirky side of AI. And yes, the class loved this idea. Instead the comments it produced were a bizarre mix of words, somewhat nonsensical yet oddly recognizable, following a pattern like "yur mom said that or else." Back then, the concept of Generative Pre-trained Transformer (GPT) was just a white paper titled "Improving Language Understanding by Generative Pre-Training." Little did we know, we were barely scratching the surface of what these LLMs could achieve.
Fast forward to today, LLMs like GPT-3/4 are solving problems that range from writing essays, coding, and even creating art, to more nuanced applications like supporting mental health chatbots and predicting protein structures, illustrating the vast potential of these AI marvels.
Fine-Tuning LLMs
Fine-tuning an LLM is like teaching a general practitioner to become a specialist. For instance, a tech company wants to develop a chatbot that can provide expert legal advice. They can't just rely on a general LLM; it needs to understand legalese as if it passed the bar itself. So, they fine-tune a model using a curated dataset of legal documents, case studies, and expert analyses.
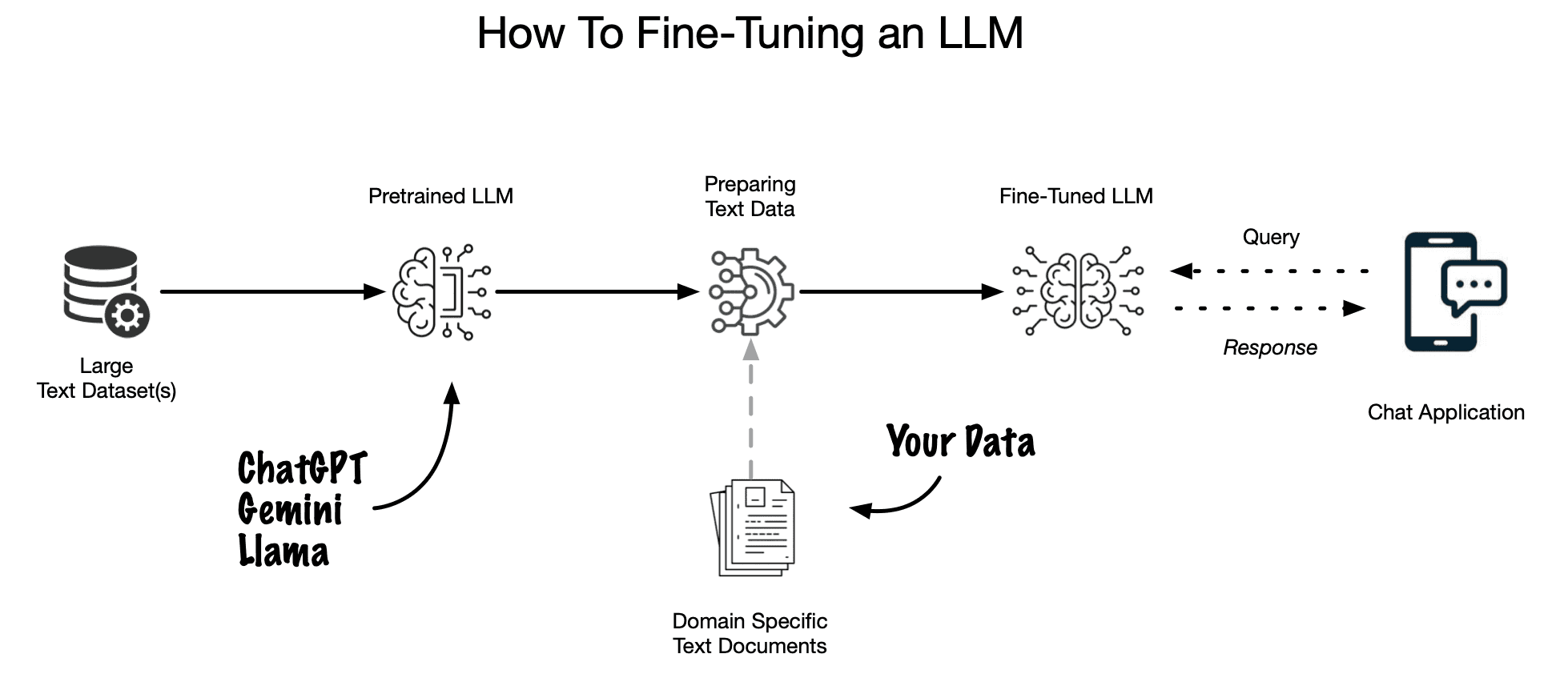
To prepare for this, a company must first amass a targeted dataset that's representative of the queries and scenarios the chatbot will encounter. This might involve gathering thousands of legal documents, FAQs, and other relevant texts. The data must be cleaned and structured, ensuring it's free from biases and inaccuracies. Then, this dataset is used to fine-tune the LLM, honing its abilities to understand and generate legal advice, making it a specialized tool tailored for the legal industry.
Fine-tuning an LLM for a legal advice chatbot involves training the model with a dataset meticulously compiled and structured to cover the spectrum of legal knowledge and inquiries it might encounter. This dataset is not just a random collection of legal documents; it's a curated selection that aims to encapsulate the breadth and depth of legal knowledge in a structured format conducive to learning.
Examples of Training Data For LLMs
Let's consider the type of data used for fine-tuning:
1. Case Summaries: Short, concise summaries of legal cases, providing the model with context, decisions, and key legal principles. Each summary might include fields like 'Case Name', 'Summary', 'Legal Issue', 'Decision', and 'Key Principles'.
2. Legal FAQs: A collection of frequently asked questions and their corresponding answers, which helps the model learn the typical format of user inquiries and the appropriate way to respond. This could include fields like 'Question' and 'Answer', with the content being a mix of layman's terms and legal jargon to accommodate various user backgrounds.
3. Statute and Regulation Excerpts: Sections of legal statutes and regulations, annotated to highlight their application and interpretation. This might include fields such as 'Statute Name', 'Section', 'Text', and 'Interpretation'.
4. Client Consultation Transcripts: Anonymized transcripts from client consultations, offering insights into the interactive dialogue between a lawyer and a client. These could have fields like 'Question', 'Response', 'Context', and 'Legal Outcome'.
Formatting and Structuring Data
The data is typically formatted in a JSON or CSV format, where each entry is structured to provide clear, distinct fields. For example, a JSON entry for a legal FAQ might look like this:
{
"Question": "Can I write my own will without a lawyer?",
"Answer": "Yes, you can write your own will, but it must meet your state's legal requirements to be valid. Consulting with a lawyer is advisable to ensure all provisions are in order."
}
This structured format allows the LLM to understand the relationship between questions and answers, facilitating its ability to generate accurate and relevant responses. However, this isn't the only way you can fine tune and not just lawyers can benefit from having their own domain-specific knowledge accessible within the scope of their AI applications.
Other Applications of Fine Tuning
1. Question and Answer Applications: By training with a Q&A format, the LLM learns to anticipate user inquiries and generate informative, precise answers. This directly improves its effectiveness in chatbot applications, where users expect quick and accurate legal advice.
2. Document Summarization: Training with case summaries enables the LLM to condense lengthy legal documents into concise summaries, aiding users in quickly grasping the essence of legal texts without sifting through extensive documents.
3. Legal Research: When trained with statutes and regulation excerpts, the LLM can assist users in navigating complex legal frameworks, offering insights into how laws are interpreted and applied.
4. Multi-task Optimization: This is a mouthful but bascially, an example would be to have a finetuned model identify key people in a litigation summary, identify the subject of the case such as criminal, family law, civil, etc, and then predict who benefited more from the outcome. Each of these actions you request the model to complete would be a "task" and the fact that you ask the model to do many of them at once. Finetuning helps the ability of the model to carry out these tasks more successfully especially if your data is contextually relevent and cohesive with these tasks moreso than the orignal data the LLM was built with.
By fine-tuning with this targeted strategies, the LLM becomes a specialized tool, equipped not just with a broad understanding of legal terminology but also with the nuanced capability to engage in meaningful legal discourse, providing users with reliable, context-aware legal advice.
Automated Training Data for LLMs
To create your own dataset for finetuning tasks can be tedious and costly, however there are options available to automate the preparation of domain-specific text which span from traditional natural language processing methods and even using another large language model to prepare the training data for you. In our own enterprise, we might have data in different systems and applicaitons.
You might have your own set of documents, support ticket requests and resolutions, or just a giant batch of documents with some kind of knowledge that you've accumulated over the years that doesn't fit neatly into this "Q&A" format that you would have to construct somehow. There are several approaches to taking yoru existing text data and transforming into usable training data for fine tuning an LLM such as ChatGPT, Gemini, or Llama. Generally, the idea is to build a process that takes your existing data and segments it in the right way or summarize parts of it to use.
Here's a basic summary of what these steps might look like.
Step 1: Text Segmentation First, segment the document into manageable units, such as sentences or paragraphs, which will serve as the basis for generating questions and answers. Each segment should ideally contain a complete idea or fact.
Step 2: Key Information Identification Identify key pieces of information within each segment that could serve as the focus for questions. This might involve recognizing named entities, key phrases, or main ideas using NLP techniques like named entity recognition (NER) or keyword extraction.
NER just means Named Entity Recognition and it involves identifying key ideas, words, or phrases within your data to make it easier to identify areas of interest. NLP is natual language processing and it's a branch of AI within Machine Learning that helps us work with text data.
Step 3: Question Generation For each identified key piece of information, generate a question. There are several approaches to this:
Rule-based: Use predefined templates to transform statements into questions. For instance, if a sentence is "The software requires 2GB of RAM," a template could convert this into "How much RAM does the software require?"
Machine Learning-based: Utilize a machine learning model trained specifically for question generation. This model can take a sentence or paragraph as input and output a relevant question. Models like T5 (Text-to-Text Transfer Transformer) can be fine-tuned for this task.
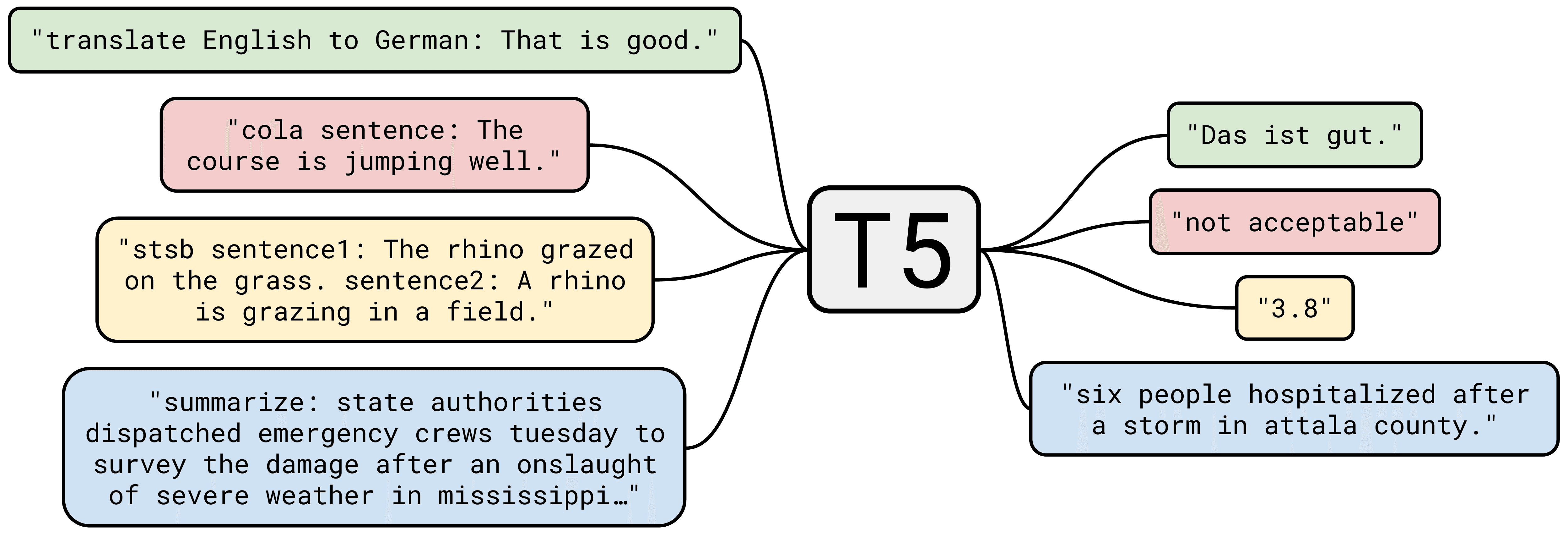
T5 (Text-to-Text Transfer Transformer): Imagine T5 as a highly skilled translator that can understand and rewrite any piece of text into something else. This could be turning a sentence into a question, summarizing a long paragraph into a short one, or translating English to French. T5 is trained to handle various tasks by learning from lots of different examples, making it quite versatile in dealing with language.
Example of T5's Usage: If you have a sentence like "The cat sat on the mat," and you want to ask a question about who sat on the mat, T5 can help transform that sentence into a question like "Who sat on the mat?" This is particularly useful for creating things like quizzes or helping to generate questions based on text, making it easier to find specific information or test understanding of a topic.
- Use of QA Datasets: Leverage existing QA pairs from similar domains to train a model that can generate questions from new content. The model learns the style and structure of questions from the dataset and applies this to generate new questions.
Step 4: Answer Extraction The answer to the generated question is typically the segment of text from which the question was derived. However, you might need to refine the answer, ensuring it's concise and directly addresses the question.
Step 5: Validation and Refinement It's crucial to validate the generated QA pairs to ensure they make sense and are accurate. This step might require manual review or semi-automated methods where a model checks the relevance of the QA pairs.
Example:
Input Text: "The software requires 2GB of RAM to operate efficiently."
Key Information: "software requires 2GB of RAM"
Generated Question: "How much RAM is required for the software to operate efficiently?"
Answer: "2GB of RAM"
Trade-offs in Automatic Question Generation:
| Approach | Pros | Cons |
|---|---|---|
| Rule-based | Simple to implement; easy to interpret. | May not handle complex sentences well; limited variability in question types. |
| Machine Learning-based | Can generate a wide variety of question types; adapts to different contexts. | Requires substantial training data; might generate irrelevant or inaccurate questions without fine-tuning. |
| LLM-Based | Can summarize and adapt any kind of text realitively easily. | Can be slow and expensive depending on the volume and complexity of your data. |
| Using QA Datasets | Leverages domain-specific knowledge; potentially more accurate in context. | Limited by the scope and quality of the existing dataset; may not generalize well to unrelated content. |
By following these steps and considering the trade-offs of each approach, you can generate a robust dataset of question-answer pairs to fine-tune your LLM or NLP model for a wide range of applications, from chatbots to automated support systems. Since no two projects or datasets are the same, it's important to review which areas have the most value and part of starting projects like this is doing an exploratory project to understand the objectives you want to achieve matched against specific use cases.
Last, But But Not Least: How Do You Know if Fine-Tuning Was Good?
Evaluating the Success of Your Question Generation Model
After creating your question generation model, it's important to check how well it's performing. Think of this like grading a test; you want to know how your model scores! Here are some ways to evaluate your LLM model, explained in simpler terms:
1. Accuracy: This is like checking how many answers your model got right. It measures the number of questions that are correctly generated and relevant. Sometimes, you might need to look at the questions yourself to see if they make sense.
2. BLEU Score: Imagine you asked a friend to rewrite a sentence and then compared it to a few other good ways to rewrite that sentence. The BLEU score does something similar by comparing the questions your model generates to a set of good example questions. It's a way to see how well your model's questions match up with what we'd expect.
3. ROUGE Score: This is another way to compare your model's questions to example questions. It checks how many words or phrases are common between the two, giving you a sense of whether the model's questions are on the right track.
4. Diversity: Just like a good quiz has a variety of questions, this metric checks if your model is creative enough to come up with different types of questions. A higher score means your model is not just repeating itself but is coming up with unique questions.
5. Human Evaluation: Sometimes, the best way to check something is to ask a person. Getting feedback from people, especially those who might use your model, can help you understand if the questions are useful, clear, and relevant.
Before wrapping up, remember that testing your model is an ongoing process. Just becauce you've fine-tuned, doesn't mean it's time to hang up your hat and move on. Evaluating and maintaining your fine-tuned work of art is an ongoing task and will take some effort to get right. Just like learning, improving your question generation model is a journey. By regularly checking its performance with these metrics, you can help it get better over time, ensuring it provides valuable and accurate questions.